gRPC at CoreOS with Brandon Philips
Brandon Philips, CTO of CoreOS, tells your cohosts Mark and Francesc why they chose gRPC for the newest version of etcd and how this improved its performance and development flow.
About Brandon
Brandon Philips is helping to build modern server infrastructure at CoreOS as CTO. Prior to CoreOS, he worked at Rackspace hacking on cloud monitoring and was a Linux kernel developer at SUSE. As a graduate of Oregon State’s Open Source Lab he is passionate about open source technologies.
Cool things of the week
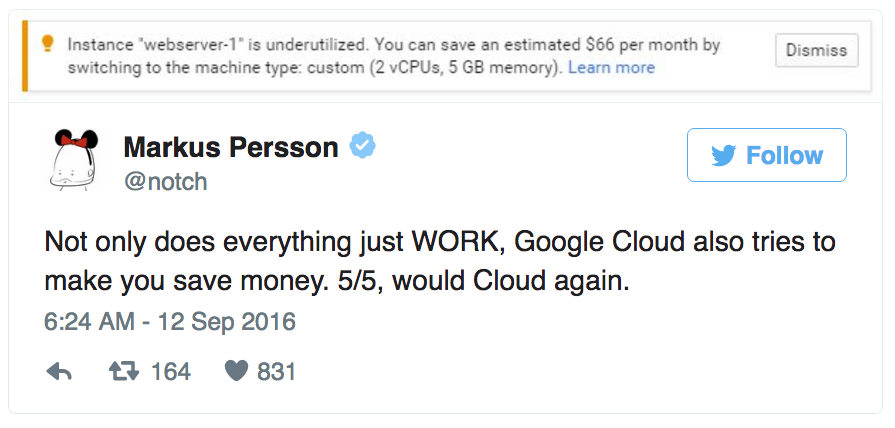
- @notch, creator of Minecraft would cloud again with Google Cloud Platform
A Stack of Stuff for .NET developers:
- Getting started with Cloud Tools for Visual Studio blog post
- Running Powershell on Google Cloud SDK blog post
- Installing and using Cloud Tools for Visual Studio YouTube
Interview
- CoreOS
- etcd: Distributed reliable key-value store for the most critical data of a distributed system GitHub
- Protocol Buffers Google Developers
- gRPC v1 GitHub release
- gRPC gateway: gRPC to JSON proxy generator GitHub
- CoreOS Community homepage
- Swagger aka OpenAPI
- gRPC streaming docs

Question of the week
- Emulator for Datastore docs
Transcript
show full transcriptFRANCESC: Hi, and welcome to episode number 43 of the weekly Google Cloud Platform podcast. I am Francesc Campoy and I'm here with my colleague, Mark Mandel. Hey, Mark.
MARK: Hey, Francesc. How are you doing today?
FRANCESC: I am, as always, very happy. Very happy. We have one of my friends Brandon Philips, CTO of CoreOS.
MARK: Yeah. He's going to come talk to us about how they used gRPC at CoreOS. It's a really interesting conversation.
FRANCESC: Yeah. Specifically about etcd but also it was like, are you using it somewhere else? A very, very interesting conversation, really.
MARK: Yeah. And how they really made the decision to make that move over, as well. Pretty cool.
FRANCESC: Yeah. Why GRPC, not REST? Why not something else? Very interesting. I'm sure people will like it. And after that, we'll have one question of the week, which is about Datastore.
MARK: Yeah. Local testing with Datastore.
FRANCESC: Yeah. We don't talk that often about Datastore, so I like it that we're going to be mentioning something as basic, really, as storing data. How do you test storing data and make your test not be flaky?
MARK: Yep. Sounds really good. But before we get into that, we have our usual cool things of the week.
FRANCESC: Yeah. It's being renamed. Yeah.
MARK: It's now cool things of the week. Absolutely. The first one-- it's just a huge favorite of mine. A gentleman by the name of Notch-- or his real name.
FRANCESC: Apparently, he actually has a name.
MARK: Yeah. Markus Persson-- if you know Minecraft at all--
FRANCESC: I've heard about it.
MARK: Yeah, it's a thing. It's a thing. I just have to mention it because he tweeted today about Google Cloud Platform. He said, not only does everything just work, Google Cloud also tries to make you save money. Five out of five, would Cloud again.
FRANCESC: Yeah, which is a pretty amazing tweet. I also really like-- I went through all the tweets he wrote about the topic. And he also said, the main thing I like about Google Cloud-- it's super-duper user friendly. So I think that this is also an invitation-- an open invitation for Notch to come talk to us.
MARK: Yeah. Notch, if you're listening, we would love to have you on the show.
FRANCESC: Please.
MARK: Please. Please come.
FRANCESC: That'd be pretty awesome. And we said there was cool things of the week, so there's a second one.
MARK: There's a second one. This is also kind of cool. I am not a .net or Windows developer, but we have some new tools available for those people that are, which I think is really, really awesome.
Those people who are used to running PowerShell inside a Windows environment, I hear it's kind of spiffy. There's a bunch of G Cloud command line tools that are available now for handling UGCE instances, Cloud SQL instances, and your Cloud storage buckets. So if you want to manage your Windows instances, say, through your command line client, you can do so, which I think is really, really neat.
And the other tool that we also have available is the Cloud tools for Visual Studio. Right now, it's pretty simple. It's just, basically, a Google Cloud Explorer.
So again, same subset of features-- Compute Engine, Cloud SQL, and Cloud Storage. You can actually go see in there and be like, OK, what pieces do I have? What zones are they in? What regions are they in? And you have a nice way of visualizing it right through your IDE there in Visual Studio.
FRANCESC: Yeah. And on top of that, there's also Cloud minute videos. I think we've never mentioned them. But they're basically just one-minute video.
MARK: Yeah.
FRANCESC: And they teach you how to do something very specific. We have one about how to install Cloud tools for Visual Studio. So we'll have a bunch of links from the show notes to all of those resources. So if you are a Windows developer and you use .net tools on Google Cloud, that will be very useful for you, I'm sure. And I think that it is time to go talk to Brandon Philips from CoreOS.
MARK: Sounds good to me.
FRANCESC: [INAUDIBLE]. So I'm very excited to welcome to the podcast a friend of mine and CTO of CoreOS. Hi, Brandon-- Brandon Philips. How are you doing?
BRANDON: Great. Thanks for having me.
FRANCESC: It's always a pleasure. I guess that most people know what CoreOS is, but could you tell us what CoreOS and what do you do at CoreOS?
BRANDON: Sure. CoreOS is a company that's building a bunch of distributed systems software. And people have probably heard of us for a few different products. Quay.IO is our container registry, CoreOS Linux-- the namesake of the company-- is a operating system for running containers. And Tectonic is a distribution of Kubernetes.
FRANCESC: Cool. And could you tell us a little bit about what do you do at CoreOS?
BRANDON: Yeah. My role at CoreOS is CTO. We started the company with the vision of, how do we rebuild infrastructure software and make it easier to work with and easier to secure infrastructure software and that sort of thing. And so, been pursuing that mission as software engineer, as architect, as open source leader-- that sort of thing-- for the last three years.
MARK: Awesome. Well, I know that CoreOS has a very popular-- definitely, here at Google-- product called etcd. Can you tell us a little about what that is and what it's used for, and where people use it?
BRANDON: Sure. etcd is a consensus key value store. For a lot of folks, that is a large mouthful of words. But really what it means is that a set of machines inside of a data center-- let's say you have five machines-- are able to store data. They're able to do it consistently.
And if one of those machines dies or loses power or whatever, the key values that were stored there are in the exact same state replicated in the exact same way on the other machines. And this is really important because you want to start to do things-- when you have lots of machines, you want to make a decision and you want to ensure that decision is replicated and consistent across all the machines. So you want to take a lock, or you want to update some load balancer configuration, or you want to update some DNS configuration, you want to ensure that there's only one true configuration of the cluster, particularly as you scale off to lots of machines inside of your infrastructure.
FRANCESC: Cool. I have an extra question about etcd, which is what does it mean?
BRANDON: Sure. We were trying to be really cute with the name. The idea is that you hold on to really important cluster configuration, but it's a daemon. It's like a system service. And so slash etc on a single machine-- like e-t-c-- is where you hold onto configuration of a single host. But in the case of a daemon, you're going to want to hold on to that same data, so it's etc- daemon. Etcd.
FRANCESC: That makes sense. Cool.
BRANDON: Yeah. Product marketing wasn't a strong suit of CoreOS when we were four people.
MARK: And since coming from me it'll seem less biased, what language is etcd written in?
BRANDON: etcd is written in GO.
MARK: Nice.
FRANCESC: Yeah, that's actually how I heard about etcd for the first time. And then, some time ago, I saw a talk where you explained how etcd was moving from REST to gRPC.
BRANDON: Yes. etcd-- when we started to build etcd, one of the goals-- we had three goals. One of the goals was we wanted to make distributing systems easy to consume. And that goal was achieved by using REST. We wanted to make it so that it was runtime reconfigurable, so it fits into these Cloud environments, so you can add and remove members from the cluster and that sort of thing. And then, we wanted to build it using modern technologies and modern languages.
And so we started with REST as an easy-to-consume end point. But as etcd started to get adopted by projects like Kubernetes, which have larger and larger scaling requirements, the REST decision ended up becoming a bottleneck. It started to show up as one of the factors in the scaling and performance of etcd.
And so we started to look around at various solutions and gRCP was open sourced about 18 months ago, at least when we started to look at it. And so we'd already started using Protobuf as the internal protocol. And layering on HTTP 2 and Protobuf on the client protocol as an option was pretty compelling, in order to flatten out that kind of growth in memory and CP consumption that we were seeing as we were trying to scale etcd up to large Kubernetes workloads.
MARK: That's interesting. What sort of scaling or performance increases were you able to see moving over gRPC?
BRANDON: Yeah. We saw several-- like 10-- well, let's see. It was like 2 to 5x on memory and CPU improvements by moving over. And really, it just comes down to-- etcd has a lot of complex data structures that get encoded to JSON. So just simply moving to a format that's more efficient, like Protobuf, causes less chatter on the wire, less bytes when you're trying to encode it, and that sort of thing. So it's really a pretty straightforward, understandable-- how we got there with the improvements.
And then HTTP 2-- we were able to see-- really, a big concern in these databases is file descriptors. So as you get more and more users of your database, which is great, there's natural constraints of an operating system. And one of those things is file descriptors. And so being able to multiplex lots and lots of requests from a single client onto a single TCP stream was a nice win on, actually, the inside of the CPU memory side-- the operating system networking side-- of the system.
MARK: Cool. And is this available now in etcd or is this something that's coming in a future version? What's the timeline there?
BRANDON: Yeah. etcd V3, which was released about three months ago, introduced the V3 API, which is accessible as both a REST API and as a gRPC API. So it's available today. It's being used in a lot of projects. We did upstream work in Kubernetes to enable V3 usage.
And then, because gRPC has all these great language bindings, we're actually starting to see things like a Java client come out for etcd V3 and a bunch of other clients that got built automatically. So it's been a nice adoption curve over the last two or three months as we released etcd V3.
FRANCESC: Cool. You mentioned that the V3 API is both in gRPC and REST. How do you manage that?
BRANDON: Yeah. The way that we do that is-- there's a really great project that is called the gRPC gateway. And the cool thing about gRPC is that it's very declarative. And it declares, essentially, the verb, the noun. The nouns-- like what are you actually operating on?
And you're able to-- using this gRPC gateway library-- you're able to flatten that down into a REST endpoint So you're able to say, well, this function call that I'm going to have into gRPC-- it's acting on this resource. And I want to map this function call to a put or a post on this resource. And the resource name ends up becoming arguments, or the resource path ends up becoming arguments to the function call.
And so you're able to flatten, very nicely, gRPC into REST. And so this gateway-- what it does is that it will expose not just a REST end point that maps through gRPC OA, but also an open API, which was previously known as Swagger. But it'll give you a Swagger document. So you can consume it in a variety of languages that already know how to speak to Swagger enabled REST end points.
So it's a quite powerful little framework if you want to start building internet-accessible APIs. You get all the best of the world REST availability, and then the efficiencies and memory efficiencies of gRPC for clients that care highly about that.
MARK: I'm curious. It sounds like using gRPC and rest for external-- API calls from external parties. Does it use it for internal communications, as well, between like etcd servers?
BRANDON: Yeah. Inside of etcd, before we even started to look at gRPC, we had already moved to a streaming Protobuf based protocol, internally. So essentially, it's already HTTP plus Protobuf on the wire as the content type.
And so, since the etcd machines-- there's only like five or seven of them in a cluster, essentially, as maximum, we're able to stream really efficiently with single HTTP connections, internally, and already using Protobuf. So we sort of have a pseudo-gRPC protocol, internally. And we haven't really had a need to redesign that because of the streaming nature of how etcd actually does its work.
FRANCESC: Cool. Is it efficient to expose the REST API through that gateway? Does it actually make it much slower, or is it around the same speed as actually exposing REST directly?
BRANDON: Yeah. There's two considerations. The first consideration is that we do have to do a little bit of packet sniffing to figure out, is this a HTTP 1 REST request or is this an HTTP2 gRPC request? That introduces a tiny bit of latency on the initial connection. But it's a constant time small latency, so we really don't worry about that-- and a couple extra memory copies.
As far as the efficiency-- yeah. Essentially, by using the REST end point, you lose a lot of the efficiencies of the new gRPC API. So you go back to encoding and decoding JSON and you lose the ability to, say, multiplex multiple streaming requests over the same socket. So you have that TLS bring up time and tear down time. So it is quite a bit more efficient-- that same 2 to 5x efficiency by using the gRPC end point.
FRANCESC: OK. So at the end of the day, basically, what you do is you expose a gRPC. And people that care about efficiency, they will use that one. And you're basically getting REST almost for free for anyone else that wants to use Swagger or Open API.
BRANDON: Exactly.
FRANCESC: Cool.
BRANDON: And there's a huge ecosystem around Swagger and Open API. And so it's nice to be able to bridge that world.
FRANCESC: I know that consuming any API that exposes a Swagger definition is very simple and there's many tools for that. What about a gRPC API? How do you get started?
BRANDON: Yeah. Getting started with this is pretty straightforward. There are Protobuf definitions for-- or gRPC definitions, I guess-- for etcd that explain all the function calls into the remote API. And then, there are various code generators that will automatically create a client binding.
So what we've done inside of etcd was we have a GO client binding, and then we've wrapped that generated code into a slightly more nice-for-humans-to-consume API. And we're doing similar work for Java. But if folks want to build, they can just straight codegen and use the codegen directly. Or if they want to wrap it up, we're super eager to help people make easy-to-consume and human-consumable APIs for other languages. The team's eager to help.
MARK: Did you find you had to do much work from the generated code to make it pretty, so to speak?
BRANDON: Yeah. That's a great question. We did a few things. etcd has some transactional semantics. So we have transactions where it's, if this statement holds true in the database, then execute this transaction. If the statement is not true, then do this other thing.
And you usually have to do a little bit of semantic work with closures, et cetera, in order to get that to look nice. So people can totally do gets and puts and the basics of a key value store with the raw gRPC client. But once you want to get into mini transactions of that sort of thing, you want to have something that saves you from some of the boilerplate annoyances.
FRANCESC: I want to ask about the streaming API. Are using it?
BRANDON: Yes. We have-- etcd V3 has a couple of streaming end points. The most used-- or one of the biggest use cases at etcd is to actually get a change-- essentially, a stream of changes of all the keys and values. So let's talk through, say, how Kubernetes uses this.
So Kubernetes uses etcd as its primary data store. A bunch of different things are happening. Say, service discovery information is changing, resources are getting updated through the REST API, and you have all these things that may be caching that data and want to be an invalidated when something changes. And so by keeping this TCP connection open, you can create these really dynamic systems based on etcd, where key changes-- and then everyone who cares about that key change is immediately notified without any polling. And the internal protocol of etcd allows for this to be a safe operation.
You can think of etcd as being like SVN for your key value stores. So if you remember, SVN-- the revision system-- every time you made a change, it incremented the revision by one. And so etcd keeps a similar index, or revision, internally. And so you say, I want all things that have happened since the revision x, and then it streams you back all that. And then, once you get to the end of the stream, it just keeps the stream open and it will send you the next stream from x plus n, wherever you left off.
MARK: That's really interesting. What did you do before gRPC? How did you stream that data?
BRANDON: Yeah. This is one of the biggest inefficiencies of etcd with the REST end point-- that we use REST long-polling. So you would say, I want everything that's happened since x, and you would make an HTTP connection. And we'd stream everything back since x and then close the connection.
And then if you said x, and x hasn't happened yet-- this revision hadn't happened yet, it's in the future-- we would just not return an HTTP body. And then once x incremented, then we would return you the HTTP body with all the changes and then close the connection again. And so this is a very inefficient way of doing it, but it's essentially how the entire internet works today-- these extremely inefficient, constantly closing HTTP requests.
FRANCESC: OK. That sounds really interesting. I'm wondering why did you choose gRPC for etcd. If it was because you had used it for something else before or it was just because it was faster. And are you using it now for other things?
BRANDON: Yeah. We ended up choosing to gRPC for, essentially, two reasons. One is that we are interested in HTTP 2 already because of this long-polling thing. We were pretty dissatisfied with tearing down these TLS connections every time.
And then, we'd already had experience using Protobuf internally in etcd. And we were super comfortable with the tooling. And so gRPC was a pretty natural fit.
There's also some legacy reasons. CoreOS was a very, very early user of Google App Engine. And we essentially had built gRPC based on a bunch of internal stuff from Google App Engine once we had to move off of Google App Engine. And so we were really comfortable that this REST proxy model of gRPC gateway and Protobuf from our experience almost three years ago. So it was, essentially, a comfort with the tooling and confidence in the tooling that caused us to choose gRPC over a lot of the alternatives that are out there today.
And then, the other big reason was we wanted to do this codegen stuff and we saw that gRPC was building a really solid ecosystem of client binding generation tools. And we wanted to see if we could plug into that. And that's starting, like I said earlier, to come to fruition.
MARK: Cool. And to Francesc's earlier question. Are you using it for any other projects or do you plan on using it for other projects?
BRANDON: Yes. We use gRPC in a couple of different projects. Rocket is a container engine that we built and have started to work with a bunch of other folks on since then. And Rocket has an API service that exposes a bunch of information on the host.
This is stuff like, what images are available for running? What are the current statuses of the containers running on the host? That sort of thing.
And so we use gRPC in that service. And this is one of the components that we plug into Kubernetes-- where we plug Rocket into Kubernetes. So Kubernetes is using gRPC to talk to Rocket today.
And then, all of the internal customer billing systems for Tectonic.com is all based on gRPC. As soon as we've started to use gRPC in our open source projects, a lot of our back office stuff-- nobody wanted to build another REST API. So it started to be adopted pretty naturally on all of our back office work, too.
FRANCESC: Nice. That really sounds like maybe we should have you back for a different episode and have you talk about all of those different products. Those sound really cool, too.
BRANDON: Cool. Yeah. I'd be happy to do it.
FRANCESC: I had one more question, which is-- OK. If you did the-- how do you say the word?-- the migration from REST to gRPC, is there anything-- any lessons-- that you learned that you'd like to share? Any painful story or success story?
BRANDON: I think probably the most painful thing was we pretty rapidly learned by building a key value database that people wanted to store binary data. And binary data is really, really hard to store in a REST API, particularly a key value REST API, because keys are really hard to represent. You end up Basic C4'ing everything. And then the values, you end up having to somehow generally Basic C4, or something worse, into JSON bodies. And so gRPC-- because it has a native byte type and can be encoded into Protobufs has been a pretty big win there.
And then, I think people underestimate the cost of JSON in a lot of their systems. I always joke that the heat death of the universe will be caused by the last JSON being decoded, just because it's so expensive to encode and decode JSON. There are tricks that you can do to make it more efficient, but it does take a lot of CPU memory to do it. And if you're doing it a lot, you need to consider if there's more effective ways of doing it.
MARK: Yeah. Cool. Well, is-- we're running out of time just a little bit. But is there anything that we haven't mentioned or maybe you want to plug or shout out to or anything like that? Anything we might have missed?
BRANDON: No. The main shouts I'd like to give is etcd and Rocket-- if you want to play around with gRPC, they're open source projects. If you go to CoreOS.com/community, you can find out on IRC channels and mailing lists how to get involved. And then, besides that, we have a couple of upcoming events. CoreOS continues to a bunch of trainings around Kubernetes, if you want to learn about that stuff. It's at CoreOS.com/training.
FRANCESC: Cool. We'll have those links in the show notes.
BRANDON: Cool.
MARK: Absolutely. Well, thank you so much, Brandon, for joining us. It was a really great interview. I really enjoyed that.
BRANDON: Yeah. Thank you so much. And thanks for organizing everything, as well. Great questions.
FRANCESC: Thank you. Our pleasure.
MARK: It was a pleasure and a joy to have Brandon on the podcast today. Thanks so much to him for joining us. It is really good to hear from people about how they ended up at the decision to use a particular product-- in this case, the gRPC.
FRANCESC: Yeah. And it's surprising how early on they committed to it. It was before 1.0. Way before--
MARK: Yeah, way before. And I used when it was before 1.0 and--
FRANCESC: It was not that easy.
BRANDON: Now it's better. I was going to say now it's better. That's the way I was going to say it.
FRANCESC: Yeah. Huge improvement. Yeah.
MARK: Exactly. No. That's a huge endorsement for the tech. But why don't we move on to the question of the week? I think you found a particular interesting one.
FRANCESC: Yeah. This is something that I have had to do before a couple times. Imagine that you're writing an App Engine app, in GO, obviously.
MARK: Obviously.
FRANCESC: And you have some of your code that acts as the Datastore. And you want to test that what it's doing with the Datastore is correct.
MARK: OK.
FRANCESC: There's a couple ways of doing this, but it's actually kind of easy with App Engine because you basically get this fake Datastore thing that it's running there. But what happens if you're not on App Engine? What if you're using just the Cloud Datastore API?
MARK: Oh, and I might be using a GKE instance or something.
FRANCESC: Yeah. You're not on App Engine. Well, before it was kind of hard to do it. You needed to, basically, have some way of faking a server or something like that. And we fixed that by providing a Datastore emulator.
MARK: Ooh.
FRANCESC: Yep. It is super simple to use. If you're using any of the G Cloud SDKs, which are available for many different languages-- but basically, you can find G Cloud-golang, G Cloud-node, and all of those. There's a bunch of environment variables that you can set your environment to make your code point to those instead to the production environment.
MARK: Oh, very nice.
FRANCESC: And to see which ones they are, it is actually super simple, too. You just go and run from G Cloud directly. You're going to have a command, which is-- for now-- G Cloud Beta. So it's G Cloud Beta Emulator Data Store something and you can run. And when you run, you start that server. But also, end in it. And that will give you a list of variables that you need to set in your environment.
MARK: Oh, very handy.
FRANCESC: Yeah. It is very simple and that will make your test that depend on Datastore much more reliable. Because right now, if you're doing it over the network, then you're depending on the network, which is not always a good thing.
MARK: And kind of slow.
FRANCESC: Yeah. So this is going to be much faster and much more reliable, which is always good.
MARK: Yay, testing.
FRANCESC: Perfect.
MARK: Excellent. All right. That sounds really good. Thank you so much, Francesc, for joining me. What are you up to? Are you running away any time soon? Working on any fancy content?
FRANCESC: I'm working on more content for [? Just for Funk ?]. I'm working on two more episodes. One of them-- people really loved GO code reviews, so I'm going to be doing one more.
And then, the other one, I'm still not decided. But it might be also about how to write GO code. Yeah. Lots of fun.
MARK: Lots of fun. Awesome.
FRANCESC: And after that, I'm going to Brazil in November for GopherCon Brazil.
MARK: Very fun.
FRANCESC: Yeah.
MARK: Excellent.
FRANCESC: What about you?
MARK: When this episode comes out, I will have landed in St. Louis. I will be at Strange Loop. I'm doing a couple things there. They have a pre-conference coding dojo, where I'll be teaching GO there, having lots of fun with that. And then I'm going to do a game development show and tell session, which is basically just show people games that you're working on.
FRANCESC: Nice. Now that you mentioned that, actually, that made me think that by the time this episode comes out, I will be in a GitHub universe, which I think forgot because it's not really travel because it's in San Francisco. But I will be there. So if there's anyone else that wants to talk a little bit about the Cloud or GO, or whatever, come say hi.
MARK: Wonderful. Well, again, thanks so much for joining me on another podcast.
FRANCESC: Thank you, Mark. And talk to you and to you all next week.
MARK: Sounds great. See you then.
Hosts
Francesc Campoy Flores and Mark Mandel
Continue the conversation
Leave us a comment on Reddit