Big Data with Felipe Hoffa
In the eighth episode of this podcast and last of 2015, your hosts Francesc and Mark interview Felipe Hoffa. Felipe is a developer advocate for Google Cloud Platform and he specializes in Big Data.
About Felipe
In 2011 Felipe Hoffa moved from Chile to San Francisco to join Google as a Software Engineer. Since 2013 he’s been a Developer Advocate on Big Data - to inspire developers around the world to leverage the Google Cloud Platform tools to analyze and understand their data in ways they could never before. You can find him in several YouTube videos, blog posts, and conferences around the world.
Cool thing of the week
Interview
- BigQuery docs
- MapReduce: Simplified Data Processing on Large Clusters research paper
- Dremel: Interactive Analysis of Web-Scale Datasets research paper
- Cloud DataFlow docs
- FlumeJava: Easy, Efficient Data-Parallel Pipelines research paper
- MillWheel: Fault-Tolerant Stream Processing at Internet Scale research paper
- Cloud Datalab docs
- Jupyter project homepage
- Cloud BigTable docs
- Bigtable: A Distributed Storage System for Structured Data research paper
- Google Cloud Genomics docs and 23andme homepage
- Hey I just met you ... tweet
- BigQuery subreddit
Question of the week
- App Engine environment variables docs
- Kubernetes secrets docs
- Google Compute Engine metadata docs
- App Engine example code to access project metadata
- Google Cloud Storage Security and Privacy considerations docs
Transcript
show full transcriptFRANCESC: Hi, and welcome to the episode number eight of the Google Cloud Platform podcast. I'm Francesc Campoy, and I'm here with my co-host Mark Mandel. Hey, Mark. How are you doing?
MARK: I'm good, thanks. How you doing, Francesc?
FRANCESC: Pretty good, pretty good, back to San Francisco and enjoying the awesome weather.
MARK: Yeah, I'm back in San Francisco too. It's a little bit warmer than where I've been previously, so pretty happy about that.
FRANCESC: Yeah, I remember you were in Vancouver, so yeah, I can imagine. So we have a very interesting episode coming today. We're gonna be interviewing one of our dear teammates.
MARK: Yes, Felipe.
FRANCESC: Felipe Hoffa. He's a developer advocate for the Google Cloud Platform like both of us, but he specializes in big data.
MARK: Yeah, he does some really interesting stuff with big data.
FRANCESC: Yeah, so we're gonna be talking about big data. What is big data? Why is it cool? What can you do with it? What can't you do, regarding big data on Google Cloud Platform, all of those things.
MARK: Big data, so hot right now.
FRANCESC: Yup. I think it's gonna be really interesting, and we're gonna try to discuss as much as possible, but again, if people have extra questions, we're always interested on those.
MARK: Definitely. If people want to get in contact with us, let's hit them up right now.
FRANCESC: Let's go with that. So if I remember correctly, it's--on Twitter it's @gcppodcast.
MARK: Yup.
FRANCESC: On Reddit we have a subreddit, r/gcppodcast.
MARK: Yup, there's a theme here.
FRANCESC: We have a webpage. It's gcppodcast.com. We have an email, hello@gcppodcast.com, and you can find us on Google+, gcppodcast--
MARK: Plus--yeah, it's +gcppodcast.
FRANCESC: +gcppodcast, there you go.
MARK: Yeah, there we go.
FRANCESC: Easy.
MARK: Wonderful. But so yes, if you have any questions or anything else you want to send to us, please do. We love to get the comments and the feedback.
FRANCESC: Yup. Cool, so before we start with the interview to our dear colleague Felipe, let's talk about the cool thing of the week.
MARK: We have a very cool cool thing of the week, though we're a little biased, of course. It's that we took a pretty cool product, but we decided just to make it better.
FRANCESC: I know the joke, but it doesn't really work with your accent though.
MARK: It doesn't work with my accent. So currently in beta is--or is betta? Oh, God, I've just ruined it, but yes, we have version 2 of our CloudSQL product. Do we want to talk a little bit about what CloudSQL is?
FRANCESC: Sure. So CloudSQL is basically just MySQL on the Cloud.
MARK: Yeah, that's really it.
FRANCESC: That's pretty much what it is. It has some really cool features like the fact that you don't need to care about that instance working. That's on us, so you basically say, "Hey, I need one instance running," and if there's any patches or security or whatever needs to be done, it's--Google engineers will do that for you.
MARK: Yup, and if you want to, like, replicate it and do that stuff like that, It's sort of just push-button. It's just really easy.
FRANCESC: Yeah, so everything is--basically, it's like a self-driving MySQL instance on the Cloud, I would like to say.
MARK: Nice, nice, nice.
FRANCESC: Yeah, and now we have version 2, which is in beta and better. You see, with my accent you see that it works?
MARK: Yeah, with your accent it works, yeah, totally.
FRANCESC: So what's new with the beta version?
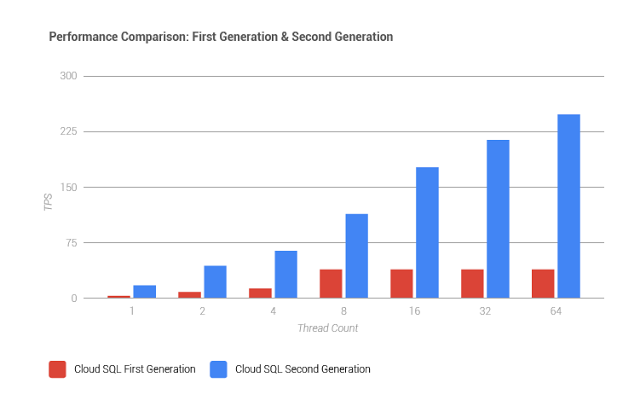
MARK: So basically it's just--really, it is just better, so it's a lot faster. It's-- I have a number here. It was, I believe, up to seven times faster than the current version, which is pretty good, and, you know, like, you don't really have to do very much above and beyond that, and it also takes--it scales out a whole lot better, up to 20 times the storage capacity of first generation.
FRANCESC: Yeah, I actually saw--there's a graphic. We'll put that in the show notes too, but there's a graphic where it shows how much it scales, and when you have enough traffic where having 64 cores helps, you're gonna see that it scales--it's much, much faster. It's able to have a way higher transaction per second count than v1. There's also, yeah, storage. It used to be 500 gigabytes, which is decent.
MARK: It's all right.
FRANCESC: Now it's 10 terabytes.
MARK: That's pretty decent.
FRANCESC: Which is pretty decent too. That's a decent amount of data indeed. So yeah, that--and that's pretty much it. It's still beta, so it's not--all the features are still not there, but we're working on them, so if you're interested on MySQL and on the Cloud, just give it a try and let us know how it goes.
MARK: Yeah, it's pretty straightforward. When you go to create your instance, just choose second generation, and away you go.
FRANCESC: Awesome. Great, so let's go with our interview with Felipe.
MARK: Let's talk to Felipe.
FRANCESC: So we're here with our colleague, Felipe. Hi, Felipe.
FELIPE: Hello, Francesc. Hello, Mark.
FRANCESC: So this is Felipe Hoffa. Tell us a little bit about yourself, Felipe. Who are you? What do you do?
FELIPE: My name is Felipe Hoffa. I'm a Cloud developer advocate.
FRANCESC: Yeah.
MARK: Cool.
FELIPE: I talk a lot about big data, especially BigQuery. I started at Google almost five years ago. Five years ago I was interviewing at this stage. I started off a software engineer.
FRANCESC: Nice, like me, actually.
FELIPE: Yeah.
MARK: Not like me.
FELIPE: Not like you, but yes, we have a similar story, and then two years later I joined the Developer Relations team, and I became a software engineer with a license to speak.
FRANCESC: With a license to speak.
MARK: I like that.
FRANCESC: That's pretty badass.
MARK: I'm gonna use that. I'm gonna use that. I like it a lot.
FELIPE: I said it first.
FRANCESC: Great. So you said that you talk a lot about big data, so we're gonna ask you just to do that. Tell us what is big data for you, at least?
FELIPE: What is big data?
FRANCESC: Yeah.
MARK: Yeah.
FELIPE: Yeah, a lot of people have tried to define what is big data.
FRANCESC: Yeah, so what's your definition?
MARK: What is the definition, like, the absolute definition?
FRANCESC: Actually, yeah, what is the definition?
FELIPE: Okay, we're at Google. We are at Google. You know how we call big data at Google?
FRANCESC: Data.
FELIPE: Exactly.
MARK: Oh, nice.
FRANCESC: I knew that. I knew that one.
FELIPE: We call it data. It being big is a very weird concept. Data has no size or weight. Some people call big data problems that are complicated, or for example, I love to asking people when I go to a conference, "Who here works in big data?" Normally people have no idea if they do
MARK: Mkay.
FELIPE: But then I ask them questions like, "Who knows SQL?" People that know SQL are people that are working with data, with databases.
MARK: Fair enough.
FELIPE: And then my next question is, "Who has had queries that run for more than an hour, for a day, or that simply don't run?"
FRANCESC: Okay, I can see, yeah.
MARK: Okay.
FELIPE: That's when we enter a different domain where problems are taking a long time, where problems are complex to solve, at least with the technologies they know.
FRANCESC: Okay.
MARK: Okay, so rather than look at it from, like, this is how much, like, terabytes or petabytes or millions of rows, rather than look at it from a perspective of, "I've got a problem. I need to solve it," when it has to do with data, but, "It's gonna take me three hours, a day, a week given the tools that I have at my disposal?"
FELIPE: Exactly. That's when people think, "Oh, this is a big data problem." Then we have the Google way of solving problems where we bring the same problem here with technologies we have created, developed here, and the same problem that might take you days using your standard toolkit might take you three seconds.
MARK: Right.
FRANCESC: Nice. So big data, finally, it's not really about the size of the data. It's really about how much time it takes you to solve a problem and how, like, standard techniques, at some point they're just not--they just don't work anymore, right?
FELIPE: Yeah, yeah.
FRANCESC: So what kind of techniques do you use then?
FELIPE: More than techniques, at this time it's about what tools.
MARK: Okay.
FELIPE: For a while, to be able to manage terabytes of data, billions of rows, people had to learn new technologies. We have, for example, MapReduce, Hadoop, Spark, Big, et cetera, but then there is a lot of complexity there. You need to wrap your mind around using parallel servers, using--developing parallel logarithms, but sometimes you just want to count things. You just want to know what are your top customers or how things are changing, so instead of going through all these technologies, today you can use technology like BigQuery where you just load your data, ask your questions with SQL, and you get the answer in seconds without having to learn a whole new mindset.
FRANCESC: Okay. So you mentioned that one of the things that we do at Google is we have internal problems. We solve them, and then we put them as available to anyone else outside. Is BigQuery one of those?
FELIPE: Yeah, well, historically we've been publishing all these papers, the MapReduce paper, the--et cetera, et cetera, et cetera. We've been through that.
MARK: Yeah, many papers.
FELIPE: Yes, and one of those papers is Dremel, how do we process terabytes of data using SQL at scale? And that paper explains the whole detail of how do we parallelize this task without making it--
FRANCESC: Okay, we'll put that in the show notes.
MARK: Definitely in the show notes.
FELIPE: Yeah, so--
FRANCESC: Yeah, that's really interesting.
FELIPE: So yeah, historically we release the papers, and the world rushes to implement them with open source implementations, but now we have Google Cloud. Now we make these services--the same services we use internally available for everyone, and that's what we're doing with BigQuery. That's the service that implements the Dremel paper.
FRANCESC: That's something--I actually heard a story about Dremel. I don't know if it's true or if it's just, like, a legend, but I heard about the fact that when Dremel was created at Google, to process 24 hours of logs was taking almost 24 hours of logs, which means that, like, if taking--processing one hour of logs takes more than one hour, then…
MARK: You've got a problem.
FRANCESC: At some point you're gonna lose logs. Like, is that true? Like, could Dremel solve that problem? Like, all of a sudden instead of hours, you go down to minutes or seconds?
FELIPE: Yes, yes. I have no idea if that is true for inside.
FRANCESC: I heard it. I don't know.
FELIPE: I know it's true for many customers. I know people that are working with huge data sets that were only able to process a small percentage of their logs through processes that run all night and fail during the night, and suddenly they try BigQuery and whoa, yeah, it takes five seconds and no babysitting of processes or anything.
MARK: So BigQuery really is, like, an example of what you were talking about before, people struggling up against walls of how much time, like, processing was gonna take and suddenly going from hours, days, weeks down to seconds.
FELIPE: Yes.
MARK: Yeah.
FELIPE: And without evolving any special knowledge.
MARK: It's just SQL, and that's it.
FELIPE: Yeah, SQL, yes.
MARK: That you have to worry about.
FELIPE: We're just talking about data.
MARK: Wow.
FELIPE: You have data. You have questions. That's it.
FRANCESC: So how do you put that data in BigQuery?
FELIPE: There are two main ways. One is batches. If you have a CSV or JSON files, you can load them into Cloud Storage if they are big enough, so it's good to go through Google Cloud Storage when you have very big files. You store them there, and BigQuery can easily ingest files from these places.
FRANCESC: Cool.
FELIPE: Or also BigQuery can ingest streaming data, so if you have any stream of realtime data come in, you can load up to 100,000 rows per second into one BigQuery table.
FRANCESC: That sounds a lot like what we were discussing last episode about messaging. We were talking about Cloud Pub/Sub.
FELIPE: Yeah.
FRANCESC: Is that the way to stream data into BigQuery?
FELIPE: That's one way. Now, Cloud Pub/Sub doesn't output data straight into BigQuery.
FRANCESC: Okay.
FELIPE: Don't ask me why, but maybe one day.
MARK: Lovely.
FELIPE: But--
FRANCESC: We'll fix that.
FELIPE: But yeah, one of our customers wrote a very nice blog post where they used Pub/Sub to ingest a lot of streaming data and they find a lot of it goes into BigQuery. Now, in the middle they used Dataflow.
FRANCESC: Oh, interesting.
FELIPE: Yes, Google Cloud Dataflow.
FRANCESC: Actually, since we're already discussing about Cloud Dataflow, so BigQuery's one of the products that with--you can do big data processing with Google Cloud Platform. What about Cloud Dataflow? What is the difference, and why could you use one or the other?
FELIPE: Yeah, so if you have data and you have questions that you can express with SQL, BigQuery's the place.
FRANCESC: Okay.
MARK: Cool.
FELIPE: Now, with Dataflow we are able to solve different kinds of problems like where you would called--or you would use Java code to write more complicated stages, and all--
FRANCESC: So is it more like MapReduce or?
FELIPE: Yeah, Dataflow is the new MapReduce. We published the MapReduce paper, like, ten years ago?
FRANCESC: Yeah. Maybe more, actually.
MARK: It was a while ago.
FRANCESC: Yeah.
FELIPE: Yeah, and since then we published two very interesting papers. One is Flume, FlumeJava.
FRANCESC: Yeah.
FELIPE: And that talks about how we orchestrate these pipelines of MapReduces and optimize them on the way, and also the MillWheel paper that deals with streaming data. Dataflow is what--it's our service that encapsulates these two ideas.
FRANCESC: Okay.
FELIPE: How do we write smart pipeline of MapReduce processes? So MapReduce has this problem that if you really want your MapReduce processes to go fast, you have to do a lot of manual optimization.
FRANCESC: Okay.
FELIPE: And Dataflow takes care of that, and you just write your pipelines as you could write them mentally, and then the optimization is part of the process. You don't have to care about optimizing things manually.
MARK: So what sort of things would I be using Dataflow for? Like, if I can get my data into BigQuery and process it there, like, can you give me an example of, like--is it, like, realtime or is it--like, what sort of stuff am I doing with Dataflow?
FELIPE: Yeah, so Dataflow has two--as I was saying, two modes. One is the batch mode.
MARK: Okay, and what is that?
FELIPE: And the other one is the streaming mode.
MARK: So what's the difference?
FELIPE: Well, you have to--before I answer what's the difference…
MARK: Sorry, no.
FELIPE: Part of the charm of Dataflow is that your same code could work for both types of data.
MARK: Okay.
FELIPE: Usually people have to deal with one system for batch processing and one system for streaming processes. With Dataflow you can do both. Just to give you a simple example of what I've used Dataflow for, when I found some web logs that were in binary format that I wanted to load into BigQuery, I needed to write some code. The logs were massive. It was billions of rows, so I had to process them in parallel, so I could write just a simple script in Java inside Dataflow, and Dataflow took care of doing this process, splitting it and writing it to many different servers.
MARK: Mkay, so you're using it sort of to do data transformations.
FELIPE: Data transformations.
MARK: And just massive data transformations though.
FELIPE: Exactly, Dataflow takes care of the parallelization, making this process smart, but what's really brilliant about Dataflow too is how it treats streaming data.
MARK: Yup.
FELIPE: So I mentioned that you can stream data into BigQuery, and you can analyze it later immediately with queries, but sometimes you want to run some online algorithms. I love the Wikipedia example where you can look at the changelog, so how many--what pages are people changing at any given time, and the question there is from a stream of--like, if you have a list of what pages are changing on Wikipedia at any time, how can you find what are relevant news?
MARK: Oh, interesting.
FELIPE: Yes, so how can you tell this change is important versus this change is not?
FRANCESC: Yup. So you could do something quite similar, like trending topics on Twitter and stuff like that. That's really interesting.
MARK: That makes sense.
FELIPE: Yeah, so there's a Googler, Thomas Steiner, that wrote a paper on this, and he looks at three things, is this page--how many changes this page has had in the last minute, how many different people are changing it, and there was a third factor that I--so it's how many changes, how many people, and how frequent are these changes, and once we surpass those thresholds, we can say, "Oh, now we have something interesting. Like, we have 50 people at the same time making changes."
FRANCESC: Yeah.
MARK: Yup.
FELIPE: And I would love to run that algorithm on a stream of data just to get realtime results.
FRANCESC: Yeah, that'd be really interesting. I can even imagine using that for monitoring of your own application, like, trying to understand, like, the same thing you can do monitoring on Google Cloud Platform of our logs and see, like, "Oh, maybe the traffic is too high. Send me an alarm." Like, you could do something more advanced.
MARK: Like, business metrics like how much money is being sold--like, being spent and how many products are being sold, so that sort of stuff.
FELIPE: So you--with Dataflow you have the ability to define some rules over some windows, sessions, time. It makes it very, very easy to start defining that kind of processes.
MARK: Now I want to play with Dataflow more.
FELIPE: Oh, yes.
FRANCESC: Dataflow is actually the only reason why I've written Java lately. Yeah, which you know it's gonna--yeah, that's a big statement for me.
FELIPE: Yeah, we also announced a Python Dataflow.
FRANCESC: Yeah, I heard about that.
FELIPE: But still not there, so.
FRANCESC: Okay.
MARK: Okay.
FELIPE: Write Java in the meantime.
FRANCESC: Okay, so we've discussed two things, BigQuery and Cloud Dataflow. I know--and now that you mentioned Python you made me think about it, it's the Cloud Datalab?
FELIPE: Datalab. Datalab, Dat-ta-lab? Yes.
FRANCESC: Depending on who you are.
MARK: Depending on which accent in the room you're gonna go with.
FELIPE: Yeah.
FRANCESC: Yeah. By the way, accent-wise today we're doing--yeah.
MARK: We've almost got a who--we haven't got quite a whole set, but we're getting close.
FRANCESC: Yeah, we're pretty good.
FELIPE: Yes. I didn't tell people where I come from, but I'll let them guess.
FRANCESC: Oh, yeah, that's--yeah.
MARK: There we go.
FRANCESC: You speak data analysis, so guess where Felipe's from. So yeah, tell us about Cloud Datalab.
FELIPE: Yeah, so if you have used the IPython Notebooks--
MARK: I've done that.
FRANCESC: Yeah, they're cool.
FELIPE: Yes, and you should call them nowadays Jupyter Notebooks.
FRANCESC: Okay, I will.
MARK: Okay.
FELIPE: Yes, that's the--
FRANCESC: Oh, that's the--
FELIPE: That's their actual name now.
FRANCESC: Oh, okay.
MARK: Okay.
FRANCESC: Cool.
MARK: Okay.
FELIPE: Yeah, IPython split this project between IPython and the notebook, and now it's the Jupyter Notebook because they support many more languages. It's not Python-specific anymore.
FRANCESC: Oh, cool.
MARK: Ah, nice.
FELIPE: Yes.
FRANCESC: Okay, I didn't know that.
MARK: Did not know that either.
FELIPE: So Jup--the Jupyter names come from Julia, Python, and R?
MARK: That would make sense.
FELIPE: Yeah.
MARK: Something like that.
FRANCESC: Yeah.
MARK: Cool, okay.
FELIPE: Yes, so if you take those notebooks--I love them. They are a great way for data scientists to work with code, data, et cetera. If you take those notebooks, how can we make them as--package them as a service? How could we have a service that immediately deploys, and Notebook, for you, takes care of storage--of storing [inaudible] repository, take care of--it takes care of authentication with the different Google services. Basically that's Google Cloud Datalab. It's our--an easy way to deploy, manage, and work with Google services inside Jupyter Notebook.
MARK: So if I'm, like, I--well, I have all this data. I want to integrate it with some of our big data tools, but I want to, like, work in, like, say, a Python environment or an R environment, something like that, and then get, like, maybe nice visualizations and that sort of thing, that's a pretty good environment for that?
FELIPE: Yes.
MARK: Perfect.
FELIPE: A pretty cool, interactive environment. Yeah, you could do the same at home with your Jupyter Notebooks, but then you need to take care of everything, installing them, authentication between your computer and a server. With this they are just running their--
MARK: It's just easy.
FELIPE: Yeah, I love them.
FRANCESC: Yeah, that sounds really powerful, especially for education and things like that where basically, you want to teach someone statistics and you have data. It's just like, you can share it. That sounds really interesting.
FELIPE: Yeah, it's one of the best ways we have now to tell people, "This is how you can work with it at Google." There are some very interesting notebooks, for example, for working with genomics.
MARK: Oh, interesting.
FELIPE: We have a lot of genomics data in BigQuery, and the genomics team has published very cool Datalab notebooks for it.
FRANCESC: That's really cool. Especially what I like is that basically, it allows you to do processing on what people are already used to. Like, many people that do data science, they do--they use Python, and they used to use IPython. Now they use Jupyter, so basically having the possibility of doing the same thing but having--being powered by the Cloud and having access to--do you have, also, access to BigQuery?
FELIPE: Yeah, yeah, yeah.
FRANCESC: Okay, so you have access to BigQuery. Do you have access--not to Cloud Dataflow 'cause that's a different technology. That's completely different, right?
FELIPE: But what about [inaudible] Python Dataflow?
FRANCESC: Oh, interesting. So can you actually combine all of those things on one single Jupyter sheet?
MARK: Thing?
FELIPE: You should be able to.
FRANCESC: Okay.
FELIPE: We're moving forwards to getting that.
FRANCESC: Cool. Just--I'll--yeah, a little announcement. Well, not really an announcement, but the Cloud Datalab is still in beta, so if people want to play with it, go see it and give your feedback. Like, when you give feedback about beta product is when your feedback's gonna be really taken into account, so if you have strong opinions about the product, let us know.
FELIPE: Yes, please try it out. It's--most of it is open source, so it's on--you can find it on GitHub. You can file feature requests. You can send patches if you follow the whole "How to contribute code to Google" steps.
FRANCESC: Nice.
MARK: That's very cool. Now, I'm looking here. Apparently we currently support, what is it? Python, SQL, and JavaScript for BigQuery user-defined functions.
FELIPE: Yes.
FRANCESC: Cool.
MARK: But it's also, like, pay for the resources you use, so you could fire this up and then run with it, then shut it down.
FRANCESC: Yeah.
MARK: That's pretty cool. Nice.
FRANCESC: No, that's very nice. Cool, so--okay, so so far we've seen, then, Cloud--no, Cloud Dataflow, Cloud Datalab, and BigQuery. Is there any other products that you think we should mention? I mean, we also mentioned Pub/Sub quite quick.
MARK: Yeah.
FRANCESC: Is there anything else that you would like to mention about?
FELIPE: It's just fun to see so many different names that people have to remember.
FRANCESC: Yeah.
MARK: Yeah. They will all be in the show notes.
FRANCESC: Yeah.
FELIPE: Yes. Usually when I say BigQuery, people remember BigTable for some reason.
FRANCESC: Oh, should we talk about BigTable?
FELIPE: We should mention BigTable. BigTable is awesome. BigTable is also another technology that from the beginnings of Google we published a paper. The world took those papers. They produce a soft--open source software based on it like HDFS and Cassandra, and then many years later we are offering BigTable as a service.
FRANCESC: Nice.
MARK: Nice.
FELIPE: And it's HDFS-compatible.
FRANCESC: Yeah, that's really cool. I mean, I think that anyone that has been working at Google as a software engineer--like, one of the things that you get to do is you get to write stuff on BigTable. It's such an amazing thing to have that I'm actually really excited to be able to use it from the outside now. Like, you can basically write your own project that uses BigTable. That's gonna be very nice.
FELIPE: Yes. Not to be confused with BigQuery.
FRANCESC: Yeah.
MARK: Different products.
FRANCESC: Yeah, so we have two bigs and two datas. So we have BigQuery and big data, Datalab and Dataflow.
MARK: I think you mean BigQuery and BigTable.
FRANCESC: Oh, yeah. Oh, that's sad. BigQuery, BigTable, Data clou--ah, Dataflow, and…
MARK: Datalab.
FRANCESC: Datalab. There you go, complicated.
FELIPE: At least none of these names sound like Pokemon.
FRANCESC: Yeah, that's--
MARK: There you go.
FRANCESC: That's good. Great, so let's talk not anymore about tools. Like, the tools I think we've pretty much done. We'd like to talk a little bit about what cool things could you have seen with big data, like, what cool data sets or what cool projects you've heard about.
FELIPE: Okay, the coolest one for me, it's--not many people can do things with it, but just knowing that people are doing genomics stuff with BigQuery, solving genomics problems with SQL, and that's--
FRANCESC: I've actually seen a video of you analyzing your own genome.
FELIPE: You saw a tweet.
MARK: So what's--yeah, what's genomics? I assume it has, obviously, something to do with DNA.
FELIPE: Yeah, so my favorite story here is when I met Jaclyn Kollar, one of our science engineer. She had joined Google, like, three months previous, and we went to the same event, and we said hi. She told me that she already knew me because when she was interviewing to work at Google, she had been watching my videos, and she used one of those videos to prepare a presentation for her Google interview, and that's how she got hired, so that was cool, and now I felt it was a little unfair because she already knew me, and I knew nothing about her, so we started talking. Then she told me about how she loves genomics, how she got her own 23andme reads, so now she had her own genome sequenced. 23andme does only a small portion of it, but still it's super cool, and she had already loaded it into BigQuery.
MARK: Okay.
FELIPE: And so I asked her, "Well, have you analyzed it? Have you done anything with it?" and she was like, "Not yet," and I asked her, "Do you want to?" because I already knew what kind of queries you could run on her genes.
FRANCESC: That's a whole new meaning to getting to know someone.
MARK: Yeah, no kidding.
FRANCESC: But that's cool.
FELIPE: Exactly.
MARK: So what sort of queries can you run?
FELIPE: So half an hour--yeah, right. Half an hour later after meeting her, I was analyzing her genes, and the basic--
MARK: No, you don't have to say the answers, but I mean, yeah, like--
FELIPE: Yeah, so there are open databases of what each gene, what each thing--read means, so you can start running joins. "Hey, let's take your special g--"
FRANCESC: Specific genes.
MARK: Yeah, right, yeah.
FELIPE: Yes, "Let's join it with this other table that says what each means, and let's start looking at, well, who are you?"
MARK: Who are you? So we could be like, "All right, let's take my genes. Let's look at Francesc's genes and see if we somehow have a common ancestor."
FELIPE: You probably have a common ancestor.
FRANCESC: Yeah, a long time ago, yes.
MARK: It's possible it could happen. I don't know.
FELIPE: Or maybe not, nothing in common. Yeah, no, but you can see things like, you know that there are people that can not tolerate eating cilantro?
MARK: Oh, yeah.
FRANCESC: I'm one of those, yeah.
MARK: And that's a genetic thing?
FELIPE: Yeah, that's genetic.
FRANCESC: And you can see it on BigQuery?
FELIPE: Yeah.
FRANCESC: That's really awesome.
FELIPE: We could use BigQuery to find out if--the probability of you liking cilantro.
FRANCESC: Now I want to play with that.
MARK: Yeah.
FRANCESC: That's really awesome.
FELIPE: Or can you twist your tongue? That's another--that's also qualified with your genes.
FRANCESC: And basically, that's, like--if you didn't do it with BigQuery, like, that could be a decent amount of data. Like, I don't know if it's big data, but it's biggish.
FELIPE: It's a lot. It's a lot.
FRANCESC: Yeah, so yeah, it could take quite a long time. How long could it take to run--like, to run one query that could tell you if I like cilantro or not?
FELIPE: with BigQuery it takes seconds.
FRANCESC: Really? Nice.
FELIPE: It's really, really fast.
MARK: That's cool.
FELIPE: I had the ability to sit down with her and--
FRANCESC: And tell her if she likes cilantro.
MARK: And so now you know her really well.
FELIPE: Well, kind of, in a way, but yeah, so I had to tweet about this.
FRANCESC: Yeah, that was very nice.
FELIPE: I wrote a tweet. That's the one that you saw.
FRANCESC: Yeah, that's the one I remember.
FELIPE: And then William Vambenepe, our prod manager replied to that tweet, and his tweet was, "Hey, I just met you, and this is crazy, but here are my genes, so SQL them maybe?"
FRANCESC: Oh, wow. Maybe I should ask you to sing that, but no, let's--
MARK: No, don't do that.
FRANCESC: Great. Any other cool big data set that you would like to plug?
FELIPE: Oh, there's so much public data, open data available now, and this year I've enjoyed playing with taxi data, all the taxi trips in New York and visualizing what happens inside a city or also social media sites, having the full story of all the 1.9 billion Reddit comments.
MARK: That's a lot of data.
FELIPE: They were collected by user Stuck_In_the_Matrix on Reddit, and then he published them, the comments. I took them, and now they're in BigQuery, so now we can analyze.
FRANCESC: So are they a public data set?
FELIPE: Yeah.
FRANCESC: Like, anyone can just go and start playing with that?
FELIPE: Yes, right now.
FRANCESC: Great.
FELIPE: Just load the query up, use your free monthly terabyte of analysis, and just start running queries.
FRANCESC: One free terabyte?
FELIPE: Yes.
FRANCESC: With a T? Wow.
FELIPE: With a T.
MARK: That's a lot of data.
FRANCESC: That's--yeah, that's big data. Okay, well, that sounds awesome.
FELIPE: And that's free, no credit card needed. Anyone can go and play with these data sets.
FRANCESC: Okay.
FELIPE: Also Hacker News if you want to see the difference or GitHub or--
FRANCESC: Okay, we'll put a link to that on the show notes. That sounds really fun.
MARK: Are there any other places you recommend if people want to go, like, looking for big data open set data, or is that giving away your special sauce of where you find that stuff?
FELIPE: I preferly love Reddit. I even started one subreddit, /r/bigquery, so all the open data sets that I know of, that I've been playing with, any stories I know related to BigQuery I put in there.
MARK: Perfect.
FELIPE: So go see everything I know, reddit/r/bigquery.
FRANCESC: BigQuery. Awesome.
MARK: Wonderful. Well, was there anything else that we haven't covered that you want to necessarily throw in there about big data or BigQuery or Dataflow?
FELIPE: I guess you will need to have me again here.
MARK: I'm sure we can do that at some point.
FRANCESC: I guess so. Well, thank you so much for being here, and talk to you soon.
MARK: Thank you.
FELIPE: Adios.
MARK: Thank you very much to Felipe for joining us for this interview today. I found that particularly interesting. I don't do a huge amount of big data stuff, so that was really great, hearing about all the products and all the things that he's been working on.
FRANCESC: Yeah, that was lots of fun.
MARK: Lots of fun, but we have a really interesting question of the week yet again. It started with a conversation I had with Andrew Watson. He was talking about sort of environment variables in App Engine, and it sort of expanded from there into sort of, "I've got, like, a password or a credential or a secret key. You know, I need to store that somewhere safe within Google Cloud Platform and be able to share that with a variety of services. What's sort of the ways I can do that or maybe even just what's the best way of doing that?" Now, I know you've got some opinions on this, Francesc.
FRANCESC: I do have some opinions.
MARK: Yeah.
FRANCESC: So yeah, so it really depends on what you are actually doing, so I know that, for instance, if you're in App Engine, there is App Engine environment variables.
MARK: That's true.
FRANCESC: That works very well, but it will be available only for App Engine.
MARK: Yup.
FRANCESC: If you're in Kubernetes, like, thing--
MARK: Good secrets?
FRANCESC: Yeah, there's Kubernetes secrets, so that's a very good solution when you are running everything in Kubernetes, but by default my go-to way of storing stuff, secrets but not only secrets, also configuration and all of those things that you want to share across all the agents of your system is the metadata service.
MARK: Ooh, that sounds interesting.
FRANCESC: Yup.
MARK: Tell me more about what that is.
FRANCESC: So it's something really simple. It's basically a way to store metadata.
MARK: Like key value pairs?
FRANCESC: Key value pairs, exactly, so you have a key which is a string and then a value which is a string. That's it.
MARK: Cool.
FRANCESC: And the good thing about it is that it's actually very safe.
MARK: Okay.
FRANCESC: It's very simple to use. It has a REST API, and it uses authentication, so OAuth 2, so you're gonna need some scopes to access it and everything, but if you're doing it from inside of Compute Engine, by default you're already authorized to do it.
MARK: Oh, that's nice.
FRANCESC: 'Cause you're actually gonna be hitting an internal endpoint, so even just cURL will work for you. If you're doing it from outside of Compute Engine, you will need to use the REST API that then allows you to access the same API but with authentication.
MARK: Oh, that's really cool. So I only thought you could access the metadata stuff, basically, from within Google Compute Engine, but you're saying, like, we can actually access that from anywhere?
FRANCESC: I did that too. I did think so too, and actually, while preparing this podcast, one of our colleagues, Sandeep, showed us that we were wrong, which is awesome 'cause--
MARK: That's great.
FRANCESC: Yup.
MARK: I love being wrong.
FRANCESC: It actually makes your life much easier. Basically, you just keep all your data in the Compute Engine metadata service, and you can access it from wherever you want.
MARK: That's really, really handy, and you can just add whatever you want in there?
FRANCESC: Yup.
MARK: And you just need to know it's secure, goes to--it's encrypted both ways and on storage too.
FRANCESC: It's incredibly simple, yeah. It's encrypted not only at REST, so once we store it, we store it encrypted, but also in transit, so while it's going from the service to your instance it will also be encrypted there, so it's really, really simple to use. If you had other things that you wanted to share like the [inaudible], imagine it's not just as simp--something quite small. It's, like, I don't know, a big file or something that you want to keep secret, then probably Google Cloud Storage.
MARK: That would work.
FRANCESC: It's just the best way to do it 'cause then you don't have limitations on the size. You can keep whatever you want, and it's also very secure, sent encrypted. It's gonna require your authentication, all of the same things, just bigger.
MARK: By the same token, I suppose you could also use DataStore or even CloudSQL if you really wanted to.
FRANCESC: Yeah.
MARK: Yeah, but it sounds like the metadata API--I mean, that sounds like it's kind of built for this stuff.
FRANCESC: Yeah, yeah.
MARK: That seems like a really good solution.
FRANCESC: It's the simplest way to do it, and yeah, I guess that the--one of the cool things of this is that, yeah, it also works outside of Compute Engine, so you can access it through REST APIs.
MARK: That is very, very cool.
FRANCESC: Yup.
MARK: Awesome. Well, this is the last episode of the year. It's a shed a little of a tear moment. I'm a little bit sad. I'm gonna--
FRANCESC: Yeah, sadness invades me.
MARK: Yeah. I'm gonna miss you for the next few weeks, but we're definitely coming back in 2016.
FRANCESC: Yeah, we're coming back the beginning of next year for more and better.
MARK: More and better. We've got a very exciting interview lined up, but I don't--I don't want to say what it is.
FRANCESC: We're gonna keep it secret, but I think it's gonna be really awesome. It's about something that I really like.
MARK: Yup.
FRANCESC: So--and it's with some--
MARK: And it's not Go. It's not Go. I'll--
FRANCESC: It's not about Go.
MARK: It's not about Go, yeah.
FRANCESC: Okay, it's not about Go. Maybe we should do something about Go too, but yeah, it's gonna be really interesting and with someone that really knows what he's talking about, so I'm very excited about this one.
MARK: Oh, sounds good, sounds good. So definitely, people, check in with us in 2016.
FRANCESC: Yup. So let's see you soon, in two weeks. See you all soon. We've finished now with our eighth episode and hoping for many more to come next year.
MARK: Definitely. We'll see you next year.
FRANCESC: See you.
MARK: Bye. [pause]
ALL: Hey, I just met you, and this is crazy, but here's my DNA, so SQL me maybe.
FRANCESC: Whoo!
Hosts
Francesc Campoy Flores and Mark Mandel
Continue the conversation
Leave us a comment on Reddit